Exploratory Data Analysis
Week 5
John Tukey (1962)

Let’s imagine a variable showing the heights of different dogs.
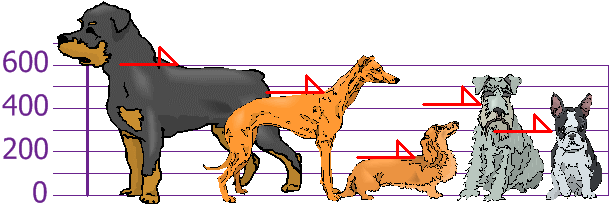
Mean is the sum of all values divided by the number of values.
AKA “average”
\(\dfrac{600+470+170+430+300}{5} = 394\)
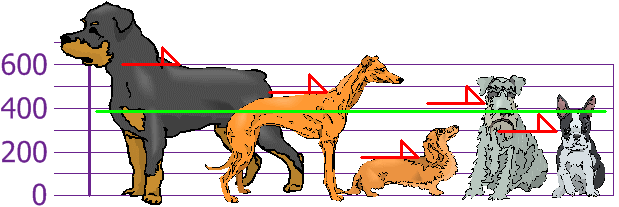
Median is the value such that half of the data lies above and below.
AKA “50th percentile”
median(dogs)The 25th Percentile is the 1st Quartile.
summary(dogs)The 75th Percentile is the 3rd Quartile.
summary(dogs)A deviation is the difference between an actual value and an estimate of location (like the mean).
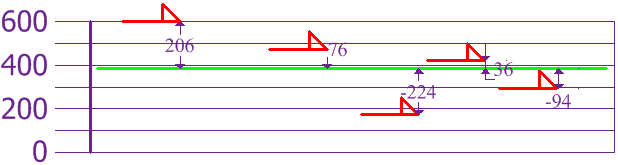
The variance is the sum of the squared deviations, divided by the number of values.
\(\dfrac{206^2+76^2+(-224)^2+36^2+(-94)^2}{5} = 21,704\)
The standard deviation is the square root of the variance.
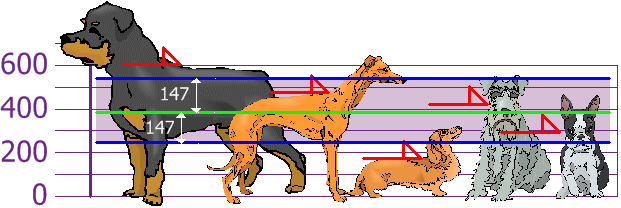
Rottweilers are tall, and dachsunds are short—compared to the standard deviation from the mean.
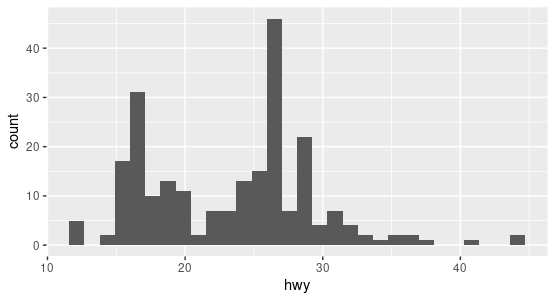
Histograms show distributions based on frequency counts.
The normal distribution has most values in the middle.
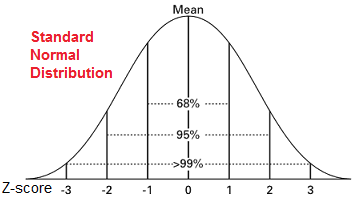
Be careful: normal distributions are assumed for many statistical analyses!
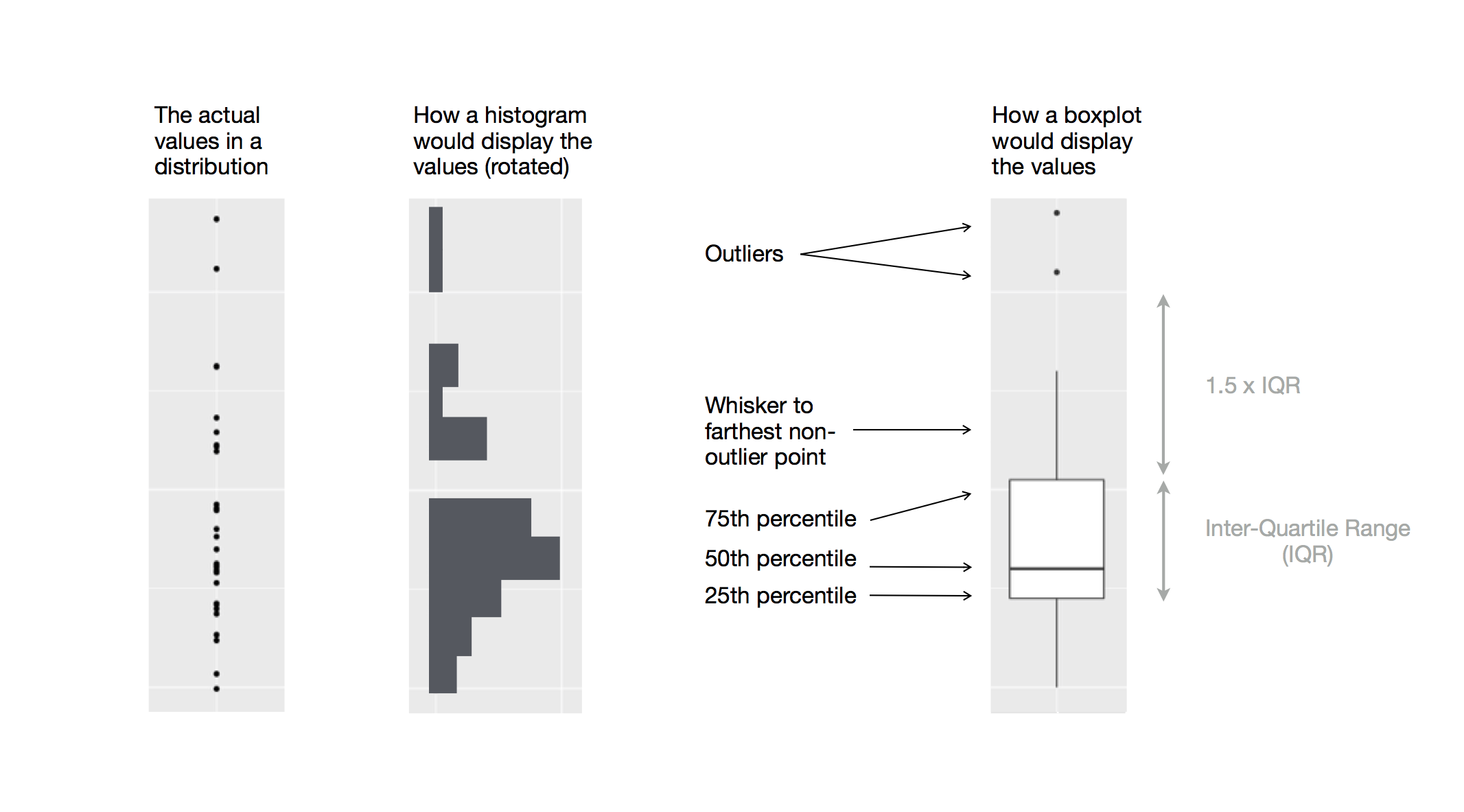
Boxplots show distribution based on the median.
Let’s look at displ and hwy in the mpg dataset
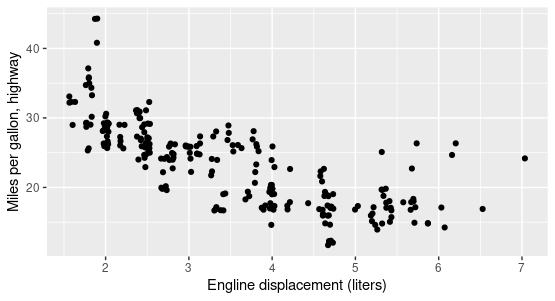
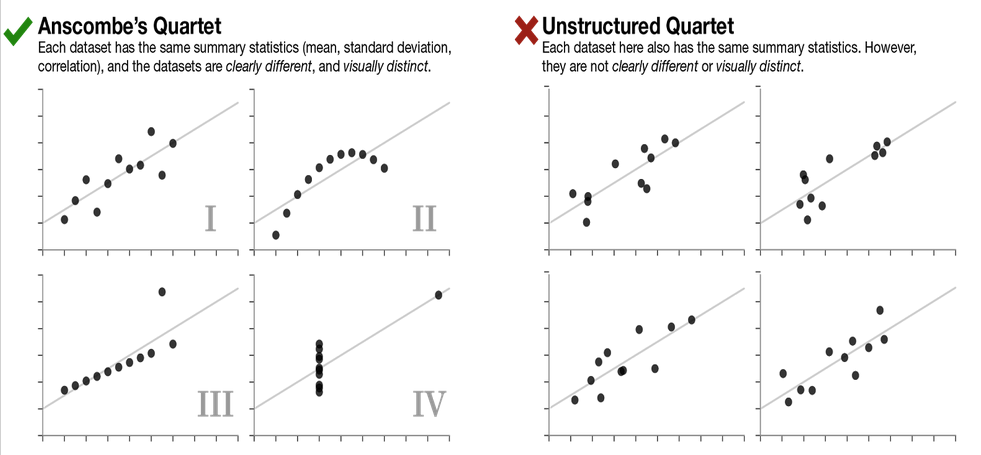
Always use summary statistics and visualization together.
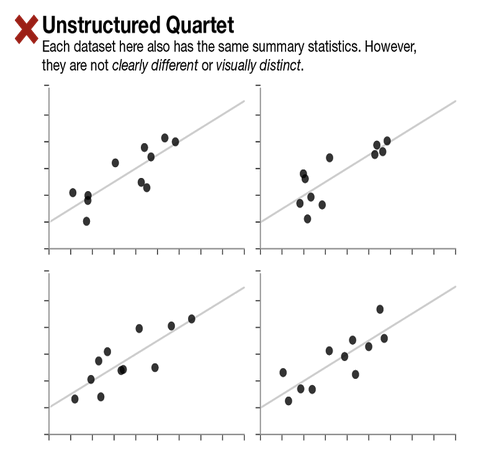
But they could very clearly and visually distinct!